Explore the Wonders of Science and Innovation at Sunday, August 17th, in Ahoy, Rotterdam
Join us for an unforgettable journey into the world of cutting-edge research and discovery. Experience the excitement of innovation at our vibrant Speech Science Festival!

Discover the World of Voice and Sound
Ever wondered how Siri understands you? Or why people have different accents? Or how your voice can be used to create music or even control robots?
As part of the international conference Interspeech 2025, the Speech Science Festival invites you—students, families, and anyone curious about science and technology—to step into the fascinating world of speech research!
Join us on Sunday, August 17th, in Ahoy, Rotterdam for this one-of-a-kind public event designed to spark curiosity, offer hands-on experiences, and bring the magic of human speech and voice technology to life. The festival takes place from 10:00 - 17:00 hours and you can drop in at any time.
If you plan to join us, we kindly request you to register. Registration and entry to the festival is free. You can register here.

🎤 What’s the Festival All About?
Speech is something we all use every day—but it’s also one of the most complex and exciting areas of science and technology. This festival will show you:
- How we produce, hear, and understand speech.
- Why people sound different depending on their language, background, or emotion.
- How computers can recognize voices, talk back, and even make music.
- How speech tech can support accessibility and inclusion.
- Why we need to design technologies that are ethical, fair, and secure.
- Are you between 10 and 18 years old? Than you might be interested in the Hackathon! During the Hackathon you will program a robot to navigate a mysterious mission from outer space...
You’ll meet scientists and engineers who work on everything from AI voice assistants to speech therapy apps, and from dialect maps to vocal robots.


Get ready to crack the code of Martian speech! In teams of three, you’ll work together to help robots navigate a mysterious mission from outer space.
No need to be a coding pro — this hackathon is about creativity, teamwork, and thinking outside the box. Plus, everyone walks away with a cool T-shirt, and each session’s winning team scores a prize.
If you’re between 10 and 18 years old and curious about how language and tech can combine, this is your chance to jump in and have fun. Are you ready to decode the unknown?
There are two sessions for the Hackathon: one from 10:15 - 11:45 and one from 14:00 - 15:30
Participation in the Hackathon requires a free registration. You can register here.

Who Can You Expect to Meet?
Academic researchers
Researchers in fields such as phonetics, phonology, linguistics, communication sciences, speech pathology, cognitive science, and computer science.
Industry professionals
The talents working on automatic speech recognition, text-to-speech, voice assistants, voice biometrics, speech data collection, inclusive speech technologies, and beyond.
What can you do at the festival?
🌟 Live Demos
Watch your voice come to life on a screen, explore how accents are detected, or try out speech synthesis tools!
🧪 Hands-on Experiments
Test your ears with speech illusions, try tongue twisters, or take part in real perception studies!
🎶 AI Song Contest
Create music with AI tools—and vote on your favorites with the audience!
🤖 Hackathon Zone
Cheer on young innovators as they design a robot for a Mars mission—powered by speech!
The Demo's
Researchers and companies from around the world will be presenting demo's covering a wide range of topics. You will, for example, see demo's on voice cloning, sound spot synthesis, speech therapy, and speech recognition. All demo's are listed below.
Indeep (by Iris Hendrickx and Daan Brugmans from Radboud University):
In this demo you will play a game where you talk to a system. The system guesses your age and emotion, and explain how it arrived at that guess! (English/Dutch)
Let's learn how we make speech sounds (by Takayuki Arai from Sophia University):
In this demo it is shown how we produce speech sounds. This is done using a physical model of the vocal tract and different sound sources. (English)
VoiceHub (by Bashir AlSaifi from DataQueue):
This demo demonstrates VoiceHub, an AI-powered call center software which is able to handle over 50 languages and 20 Arabic dialects. (English)
Open ASR Leaderboard (by Steven Zheng and Vaibhav Srivastav from Hugging Face):
In this demo you can explore how automatic speech recognition (ASR) models are evaluated and you can test a number of models yourself! (English)
Emotion recognition in speech and facial expressions (by Laura Rachman from University Medical Center Groningen):
We do not always realize it, but the speech you produce contains a lot of information about your emotion. In this demo, you will play a game where you are presented with speech containing a certain emotion. You need to click on the character who best matches that emotion! (Dutch/English)
Hey! Is that me? (by Ariadna Sanchez, Alice Ross, Artemis Deligianni, Jinzuomu Zhong from University of Edinburgh):
In this demo, you will record a samples of your speech. This speech will be used to clone your voice. You will then listen to a number of generated speech samples and judge whether the generated speech has your voice or not! There is also the opportunity to discuss your concerns and the possibilities of this technology with the researchers. (English. The recording is also possible in Dutch)
SAsa of saSA: wie heeft het gedaan? (by Hans Rutger Bosker, Matteo Maran, Roos Rossen, Floris Cos and Patrick L. Rohrer from Radboud University):
This demo shows you that you do not only use your ears to understand speech, but also your eyes! You will watch a short animated fairytale with two characters: SAsa and saSA. Can you figure out which of the two did it? (Dutch)
Dutch Automatic Speech Recognition (by Yuanyuan Zhang and Dimme de Groot from Delft University of Technology):
In this demo you can try a new automatic speech recognition system specifically trained for Dutch. If you are interested you can also help creating a new dataset for Dutch speech recognition! (Dutch)
Human vs Automatic Dysarthric Speech Recognition (by Yuanyuan Zhang from Delft University of Technology):
You will hear speech in Dutch and/or English, recordedfrom a real speaker with dysarthria. These samples were collected bythe DISC SpeechLab at TU Delft. Try your hand at transcribingthem—can you outperform our speech recognition system? We’ll rankall participants based on transcription accuracy, and top performers will have their names displayed on our whiteboard! (Dutch/English)
Good news for communication with persons with Parkinson’s Disease (by Esther Janse from Radboud University):
In this flash-talk, Esther Janse will tell you about her recent experiments in which she found that people with Parkinson’s Disease are equally fast as healthy individuals in taking their turn in conversations. (Dutch)
OriginStory (by Isabella Lenz and Visar Berisha from Arizona State University):
With the increasing quality of a AI generated voices it is becoming increasingly important to validate that the person on the other side of the call is actually a human. In this demo, you will test a new microphone system which is able to do this! (English)
Eyes on the Prize: A Speech Perception Game (by Ebony Pearson from Vanderbilt University):
In this demo you will experience real-time speech perception through a series of short, interactive tasks. The demo shows you how two dialects or languages can become active at once and how your own language shapes what you hear and how you process it.
Control Your Voice: Speech Generation and Modification (by Juliana Francis and Robin Netzorg from KTH Royal Institute of Technology, University of California, Berkeley):
In this demo a text-to-speech system is presented where different aspects of the generated speech can be controlled. You will be able to 'create' voices fitting to drawn characters! (English)
Speaking Freely: Voice Anonymization & Inclusivity (by Yamini Sinha and Ingo Siegert from Otto von Guericke University Magdeburg):
In this demo you will experience real-time voice anonymization. Voice anonymization is important for ensuring privacy, in particular for diverse communities. You can test the voice anonymization system and contribute to research on voice, identity, and privacy. (Dutch/English)
SpeakSphere (by Tobias Goecke from SpeakSphere GmbH):
In this demo you can test a real-time speech translation system from your own smartphone. The system operates entirely on local hardware, so no data is uploaded to the cloud. You can talk in your own language an witness the speech being translated in real time! (Multiple languages)
Listener Perceptions of Accented Synthetic Speech (by Stella Siu and Jan Kokowski from University of Groningen):
In this demo you will listen to synthetic speech with different accents. You can try to identify the accent and you can rate how pleasant and trustworthy you find the accent. You will get the opportunity to discuss with the researchers how accent affects listeners perception.
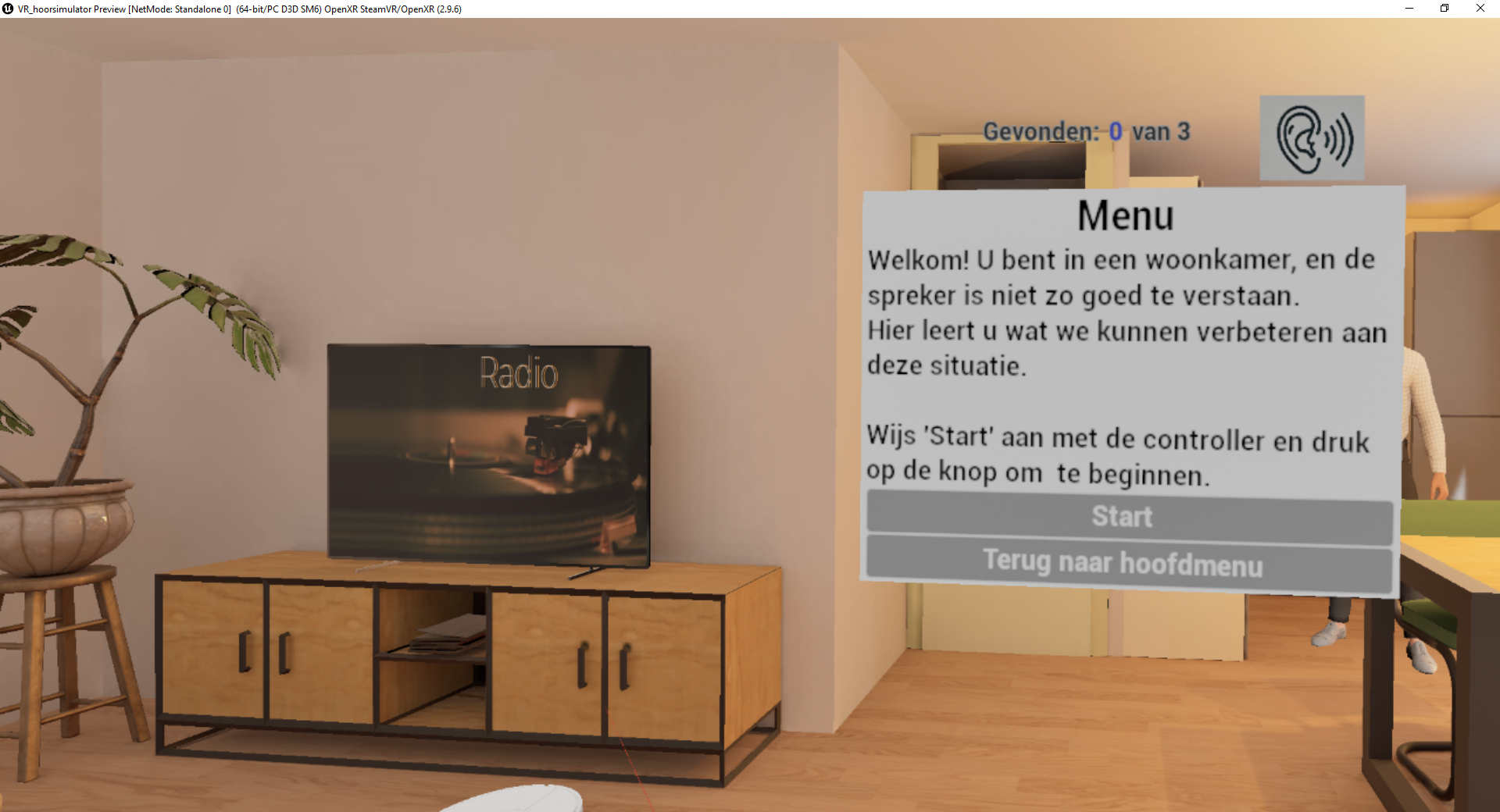
Virtual Reality Hearing Simulator (by Maartje Hendrikse from Erasmus Medical Center):
In this demo you will play a game in which virtual reality is used to let you experience what it is like to have a hearing impairment. (Dutch)
Multiple Sound Spot Synthesis (by Takuma Okamoto from NICT):In this demo you will experience sound spot synthesis. In sound spot synthesis, different listeners who are located closely together can still listen to different content. For example, one person can listen to content in English, while the other listens to content in Dutch. In this demo there are four sound spots, each with a different language, and there is real-time speech-to-speech translation. (English/Dutch/Other)
Concurrent Speech and Auditory Tag Clouds for Non-Visual Web Interaction (by Nilesh Tete and Dhia Eddine Merzougui from University of Caen Normandy):
In this demo you will interact with a computer system based on audio cues only - so the screen is not used!
You will try to complete a number of tasks such as identifying the number of audio sources.
ReflectiMate (by Morita Tarvirdians, CatharineOertel and Shambhawi Pal from Delft University ofTechnology):This demonstration present ReflectiMate, aconversational agent designed to serve as a reflection partner forpeople in the big life decision making process. The main goal ofReflectiMate is to help people to break out of their mentalboundaries and gain a more holistic view of their personal decisionmaking landscape before reaching a final decision. (English)
SLP Sidekick: Interactive Language Therapy (by Samuel Blouir, Defne Circi and Staci Chan from George Mason University, Duke University and Yale University):
You become a client in a very short, AI-guided, speech therapy session. This demo demonstrates how speech technology can help extend and streamline the workflow of a clinician, and empower home practice. (Dutch/English)
Towards Domain-Specific Spoken Language Understanding for a Catalan Voice-Controlled Video Game (by Alexandre Peiro Lilja from Barcelona Supercomputing Center):
In this demo you will play a video game where you control the character based on voice commands. (English)
Chat and Play With a Friendly Virtual Avatar (by Santosh Patapati, Aashrith Tatineni from Cyrion Labs):
In this demo you will meet an Embodied Conversational Agent which adapts voice, face, and gestures in real-time. You will be able to do one of the following tracks.
Emotion-Mirror game. The Agent makes a happy, sad, or surprised face and you need to mirror it!
Mindful Minute. The agent will help the participant name one worry, , spot the unhelpful thoughts, and then re-frame it with a helpful thought.
Voice & Accent Lab. You will read a tongue-twister and you can see the pitch, pace, and accent cues in real-time. The Agent will give you a score and you can try to improve it! (Dutch/English)
Dialpad AI Demo (by Riqiang Wang from Dialpad Inc.):
In this demo you will test a real-time speech transcription service and related tasks such as 'action-item' recognition (i.e. "turn on the lights!"). This demo also tells you more about the challenges of real-time speech recognition and telephonic speech. (English)
Prediction XR - False Negative or the Computer Says Nah (by Michaela Pnacekova and Anna Leschanowsky from Friedrich-Alexander-University Erlangen-Nürnberg):
In this demo you will learn more about the ethical risks of biometric surveillance. You do this by creating a virtual twin in Prediction XR to navigate the metaverse. The price? Surrendering your biometric data. Prediction XR discloses scoring and risk assessment systems through face and voice recognition in a playful, yet realistic way. What happens if your datafied self becomes real and influences your future? What and who gets to be perceived, and what and who gets to be silenced? (English)
A calming singing robot for people with dementia (by Paul Raingeard de la Bletiere from Delft University of Technology):
This demo showcases a singing robot which can help people with dementia to manage stress. You can play around with the pitch and the tempo to create a calmer voice! (Dutch/English)
ASR-FAIRBENCH: Measuring and Benchmarking Equity Across Speech Recognition Systems (by Anand Kumar Rai from Indian Institute of Technology, Kharagpur):
This demo showcases ASR-FAIRBENCH, an interactive leaderboard that evaluates ASR models in real time based on both accuracy and fairness. It highlights how different models perform across demographic groups, emphasizing the need for more inclusive ASR systems. (English)
JiaoJiao, A Pioneering Academia-Developed Emotional Spoken Dialogue Foundation Model (by Xun Gong, Chenyang Le, Wei Wang, and Yanmin Qian from Shanghai Jiao Tong University):
“JiaoJiao” is a large-scale emotional spoken dialogue foundation model. Unlike conventional voice assistants, JiaoJiao enables real-time, multi-speaker, multi-language, multi-role, and emotionally rich conversations, establishing a new benchmark for speech-centric AI. It combines advanced contextual understanding and question answering with real-time speaker identification, role switching, dialect perception, and emotional expression. (Dutch/English)
SCRIBAL: A Digital Transcription Tool in Higher Education (by Javier Román Pásaro and Pol Pastells Vilà from Universitat de Barcelona):
This demo shows how inclusivity can be enhanced through language technologies. SCRIBAL is a tool for real-time multilingual transcription and translation of speech in educational settings: it allows the speaker to talk in their own language, while the listeners receive the translation in real-time! (English)
Join Appen for our session exploring how innovative data collection and annotation practices drive fair and inclusive speech technologies (by Divya Giritharan from Appen):
Learn about solution design challenges and successes that enable inclusive technology for atypical speech, low-resource languages, and multi-modal communication.
Whether you’re a researcher, developer, advocate for linguistic diversity or just curious, connect with us to explore how we deploy our global network and in-house expertise to build expertly curated datasets.
Delft Science Center: Swarming Drones & Programming Robots in Minecraft
Swarming drones: In this demo drones and advanced swarm technology are used together to show you how drones can be used to do a variety of tasks: from helping people in need to exploration of unknown terrain. Watch how the drones work together like a flock of birds to solve a series of tasks!
Programming Robots in Minecraft: Learn programming in a fun way in this short workshop for kids and parents. You will jump into the world of Minecraft to figure out how computers and robots think. You will program your own digital robot to solve a series of tasks!







Morning (10:00-14:00):
Preliminary Program Highlights
Opening Ceremony on the value of science communication in the speech field
Flash Talks & Demos: Rapid-fire talks with demo's where you can engage with speech science and technology yourself!

Afternoon (14:00–17:00):
Flash Talks & Demos: Rapid-fire talks with demo's where you can engage with speech science and technology yourself!
AI Song Contest: create your own music using AI tools, and vote on your favourites!
Hackathon Highlights: A video will showcase key moments from the Youth Hackathon
FAQs
Find answers to your questions about the Speech Science Festival right here.
Entrance to the Speech Science Festival and the Hackathon is free. We do kindly request you to register if you are planning to attend the festival. If you attend the Hackathon it is mandatory to register in order for us to make the schedule. You can register here.
The festival will be held at the Rotterdam Ahoy. The address is Ahoyweg 10 3084BA Rotterdam. This is easily reachable by public transport. For more information about accessibility, visit the website of Ahoy.
The festival runs from 10:00 - 17:00 on Sunday the 17th of August, 2025. Keynote speakers and workshops will be scheduled throughout. Check our website for detailed timings.
A hackathon is an event where a group works together to try and find a solution for a given problem which usually involves (graphical) programming. In our case: helping us to understand Martian speech and to help navigate the robot! Since we only have a limited number of spots available, participation in the Hackathon requires a free registration (register here).
There are two Hackathon sessions. Both are on the 17th of August, 2025. The first session runs from 10:15 to 11:45. The second session runs from 14:00 to 15:30. The sessions are in both Dutch and English. Since we only have a limited number of spots available, participation in the Hackathon requires a free registration (register here).
The festival will consist of both Dutch and English demo's, so it is not needed to speak English (though you will be able to enjoy more demos). For the Hackathon there is both a Dutch and an English version available.
Yes, there is ample parking available at the venue. We recommend arriving early to secure a spot. Additional parking options are nearby if needed. The Ahoy website contains more details. You can also reach Ahoy by public transport.
There are a number of vending machines in the area where the festival is held. If we have enough registrations there is a possibility of opening the restaurant.